
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 715. Range Module
- iterator
- concurrency
- LeetCode
- Decorator
- 109. Convert Sorted List to Binary Search Tree
- 컴퓨터의 구조
- 운영체제
- Python Implementation
- t1
- data science
- Substring with Concatenation of All Words
- Regular Expression
- DWG
- Convert Sorted List to Binary Search Tree
- Python Code
- 밴픽
- shiba
- 시바견
- 30. Substring with Concatenation of All Words
- 315. Count of Smaller Numbers After Self
- Generator
- 43. Multiply Strings
- kaggle
- Python
- attribute
- Class
- 파이썬
- Protocol
- 프로그래머스
- Today
- Total
Scribbling
Python: Concurrency with Futures 본문
Web downloads in three different styles
- sequential download
- concurrent.futures
- asyncio
With heavy input/output workload, we can make the best out of concurrency.
Below is the code that downloads flag gif files sequentially.
import os
import time
import sys
import requests
POP20_CC = ('CN IN US ID BR PK NK BD RU JP'
'MX PH VN ET EG DE IR TR CD FR').split()
BASE_URL = 'http://flupy.org/data/flags'
DEST_DIR = 'downloads/'
def save_flag(img, filename):
path = os.path.join(DEST_DIR, filename)
with open(path, 'wb') as fp:
fp.write(img)
def get_flag(cc):
url = '{}/{cc}/{cc}.gif'.format(BASE_URL, cc=cc.lower())
resp = requests.get(url, verify=False)
return resp.content
def show(text):
print(text, end=' ')
sys.stdout.flush()
def download_many(cc_list):
for cc in sorted(cc_list):
image = get_flag(cc)
show(cc)
save_flag(image, cc.lower()+'.gif')
return len(cc_list)
def main(download_many):
t0 = time.time()
count = download_many(POP20_CC)
elapsed = time.time() - t0
msg = '\n{} flags downloaded in {:.2f}s'
print(msg.format(count, elapsed))
main(download_many)
With concurrent.futures, we can exploit multiple threads.
import os
import time
import sys
import requests
from concurrent import futures
MAX_WORKERS = 20
POP20_CC = ('CN IN US ID BR PK NK BD RU JP'
'MX PH VN ET EG DE IR TR CD FR').split()
BASE_URL = 'http://flupy.org/data/flags'
DEST_DIR = 'downloads/'
def save_flag(img, filename):
path = os.path.join(DEST_DIR, filename)
with open(path, 'wb') as fp:
fp.write(img)
def get_flag(cc):
url = '{}/{cc}/{cc}.gif'.format(BASE_URL, cc=cc.lower())
resp = requests.get(url, verify=False)
return resp.content
def show(text):
print(text, end=' ')
sys.stdout.flush()
def download_one(cc):
image = get_flag(cc)
show(cc)
save_flag(image, cc.lower() + '.gif')
return cc
def download_many(cc_list):
workers = min(MAX_WORKERS, len(cc_list))
with futures.ThreadPoolExecutor(workers) as executor:
res = executor.map(download_one, sorted(cc_list))
return len(list(res))
def main(download_many):
t0 = time.time()
count = download_many(POP20_CC)
elapsed = time.time() - t0
msg = '\n{} flags downloaded in {:.2f}s'
print(msg.format(count, elapsed))
main(download_many)
With concurrency it only took 1.55s, almost 10 times faster than sequential download.
with futures.ThreadPoolExecutor(workers) as executor:
res = executor.map(download_one, sorted(cc_list))executor.__exit() calls executor.shutdown(wait=True), which blocks until every thread is completed.
executor.map initiates Future objects, schedules loop, and retrieves results.
If further customization is needed, we can replace executor.map with below.
For example, executor.map returns results in the exact order they were called. If you want to retrieve each result as soon as it is completed, you should use executor.submit() and futures.as_completed() methods.
def download_many(cc_list):
workers = min(MAX_WORKERS, len(cc_list))
with futures.ThreadPoolExecutor(workers) as executor:
to_do = []
for cc in sorted(cc_list):
future = executor.submit(download_one, cc)
to_do.append(future)
results = []
for future in futures.as_completed(to_do):
res = future.result()
results.append(res)
return len(results)
Python interpreter has GIL (Global Interpreter Lock), which allows only a single thread to be executed at a time. However, all the standard libraries related to input/output workloads can release GIL while waiting for the result, thus allowing other threads to be exectued.
In case of heavy operations, ProcessPoolExecutor might help.
with futures.ProcessPoolExecutor() as executor:
Now, we will improve previous codes so that they can handle errors.
flags2_common.py : common functions for test
flags2_sequential.py : sequential download
flags2_threadpool.py : concurrent download with futures.ThreadPoolExecutor
flags2_common.py
import os
import time
import sys
import string
import argparse
from collections import namedtuple
from enum import Enum
Result = namedtuple('Result', 'status data')
HTTPStatus = Enum('Status', 'ok not_found error')
POP20_CC = ('CN IN US ID BR PK NK BD RU JP'
'MX PH VN ET EG DE IR TR CD FR').split()
SERVER = 'http://flupy.org/data/flags'
DEST_DIR = 'downloads/'
def save_flag(img, filename):
if not os.path.exists(DEST_DIR):
os.mkdir(DEST_DIR)
path = os.path.join(DEST_DIR, filename)
with open(path, 'wb') as fp:
fp.write(img)
def initial_report(cc_list, actual_req):
msg = 'Searching for {} flag(s) from {}.'
print(msg.format(len(cc_list), SERVER))
msg = '{} concurrent connection(s) will be used.'
print(msg.format(actual_req))
def final_report(counter, start_time):
elapsed = time.time() - start_time
print('-' * 20)
msg = '{} flag(s) downloaded.'
print(msg.format(counter[HTTPStatus.ok]))
if counter[HTTPStatus.not_found]:
print(counter[HTTPStatus.not_found], 'not found.')
if counter[HTTPStatus.error]:
print('{} error(s) occurred.'.format(counter[HTTPStatus.error]))
print(f'Elapsed time: {elapsed:.2f}s')
def expand_cc_args(every_cc, cc_args, limit):
codes = set()
AZ = string.ascii_uppercase
if every_cc:
codes.update(a+b for a in AZ for b in AZ)
else:
for cc in (c.upper() for c in cc_args):
if len(cc) == 2 and all(c in AZ for c in cc):
codes.add(cc)
else:
msg = 'each CC argument must be from AA to ZZ'
raise ValueError('*** Usage error: '+msg)
return sorted(codes)[:limit]
def process_args(default_concur_req):
parser = argparse.ArgumentParser(
description='Download flags for country codes. '
'Default: top 20 countries by population.')
parser.add_argument('cc', metavar='CC', nargs='*',
help='country code (eg. BZ)')
parser.add_argument('-e', '--every', action='store_true',
help='get flags for every possible code (AA...ZZ)')
parser.add_argument('-l', '--limit', metavar='N', type=int,
help='limit to N first codes', default=sys.maxsize)
parser.add_argument('-m', '--max_req', metavar='CONCURRENT', type=int,
default=default_concur_req,
help=f'maximum concurrent requets (default={default_concur_req})')
parser.add_argument('-v', '--verbose', action='store_true',
help='output detailed progress info')
args = parser.parse_args()
if args.max_req < 1:
print('*** Usage error: --max_req CONCURRENT must be >= 1')
parser.print_usage()
sys.exit(1)
if args.limit < 1:
print('*** Usage error: --limit N must be >= 1')
parser.print_usage()
sys.exit(1)
try:
cc_list = expand_cc_args(args.every, args.cc, args.limit)
except ValueError as exc:
print(exc.args[0])
parser.print_usage()
sys.exit(1)
if not cc_list:
cc_list = sorted(POP20_CC)
return args, cc_list
def main(download_many, default_concur_req=1, max_concur_req=1):
args, cc_list = process_args(default_concur_req)
actual_req = min(args.max_req, max_concur_req, len(cc_list))
initial_report(cc_list, actual_req)
base_url = SERVER
t0 = time.time()
counter = download_many(cc_list, base_url, args.verbose, actual_req)
assert sum(counter.values()) == len(cc_list), 'some downloads are unaccounted for'
final_report(counter, t0)
flags2_sequential.py
import collections
import requests
import tqdm
from flags2_common import main, save_flag, HTTPStatus, Result
def get_flag(base_url, cc):
url = '{}/{cc}/{cc}.gif'.format(base_url, cc=cc.lower())
resp = requests.get(url)
if resp.status_code != 200:
resp.raise_for_status()
return resp.content
def download_one(cc, base_url, verbose=False):
try:
image = get_flag(base_url, cc)
except requests.exceptions.HTTPError as exc:
res = exc.response
if res.status_code == 404:
status = HTTPStatus.not_found
msg = 'not found'
else:
raise
else:
save_flag(image, cc.lower() + '.gif')
status = HTTPStatus.ok
msg = 'ok'
if verbose:
print(cc, msg)
return Result(status, cc)
def download_many(cc_list, base_url, verbose, concur_req):
counter = collections.Counter()
cc_list = sorted(cc_list)
if not verbose:
cc_list = tqdm.tqdm(cc_list)
for cc in cc_list:
try:
res = download_one(cc, base_url, verbose)
except requests.exceptions.HTTPError as exc:
error_msg = 'HTTP error {res.status_code} - {res.reason}'.format(res=exc.response)
status = HTTPStatus.error
except requests.exceptions.ConnectionError:
error_msg = 'Connection error'
status = HTTPStatus.error
else:
error_msg = ''
status = res.status
counter[status] += 1
if verbose and error_msg:
print('*** Error for {}: {}'.format(cc, error_msg))
return counter
if __name__ == '__main__':
main(download_many)
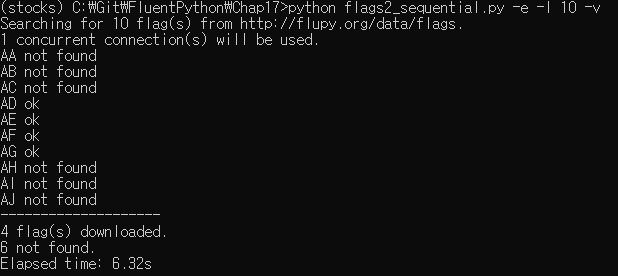

flags2_threadpool.py
import collections
from concurrent import futures
import requests
import tqdm
from flags2_common import main, HTTPStatus
from flags2_sequential import download_one
DEFAULT_CONCUR_REQ = 30
MAX_CONCUR_REQ = 1000
def download_many(cc_list, base_url, verbose, concur_req):
counter = collections.Counter()
with futures.ThreadPoolExecutor(max_workers=concur_req) as executor:
to_do_map = {}
for cc in sorted(cc_list):
future = executor.submit(download_one, cc, base_url, verbose)
to_do_map[future] = cc
done_iter = futures.as_completed(to_do_map)
if not verbose:
done_iter = tqdm.tqdm(done_iter, total=len(cc_list))
for future in done_iter:
try:
res = future.result()
except requests.exceptions.HTTPError as exc:
error_msg = 'HTTP error {res.status_code} - {res.reason}'.format(res=exc.response)
status = HTTPStatus.error
except requests.exceptions.ConnectionError:
error_msg = 'Connection error'
status = HTTPStatus.error
else:
error_msg = ''
status = res.status
if error_msg:
status = HTTPStatus.error
counter[status] += 1
if verbose and error_msg:
cc = to_do_map[future]
print('*** Error for {}: {}'.format(cc, error_msg))
return counter
if __name__ == '__main__':
main(download_many, DEFAULT_CONCUR_REQ, MAX_CONCUR_REQ)
* Future object.result() either returns value or raises exception.
* threading module and multiprocessing module can be useful for multiple threads/processes.
'Computer Science > Python' 카테고리의 다른 글
| Python: Concurrency with asyncio (asyncio 기반 비동기 프로그래밍) (0) | 2022.05.17 |
|---|---|
| Zip & Unpacking (0) | 2022.05.10 |
| Python: Coroutines (0) | 2022.05.03 |
| Python: Context Manager (0) | 2022.04.29 |
| Python: Iterator, Generator (0) | 2022.04.22 |
