
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- DWG
- concurrency
- Substring with Concatenation of All Words
- Python Implementation
- Decorator
- Protocol
- 30. Substring with Concatenation of All Words
- 715. Range Module
- LeetCode
- 컴퓨터의 구조
- data science
- 밴픽
- shiba
- kaggle
- 43. Multiply Strings
- 109. Convert Sorted List to Binary Search Tree
- Generator
- 시바견
- 운영체제
- 315. Count of Smaller Numbers After Self
- Convert Sorted List to Binary Search Tree
- Python Code
- 프로그래머스
- Class
- Regular Expression
- Python
- attribute
- iterator
- t1
- 파이썬
- Today
- Total
Scribbling
데이터 분석 방법의 기초 - Kaggle 주택 가격 예측 예제 본문
이 포스트에서는 캐글 주택 가격 예측 예제를 풀어보며,
데이터 분석 방법의 기초를 다져보고자 한다.
캐글 주택 가격 예측 예제 링크
https://www.kaggle.com/c/house-prices-advanced-regression-techniques
1. 데이터 불러오기 및 데이터 살펴보기
필자는 구글 코랩을 사용하며, 구글 드라이브에서 데이터를 불러온다.
from google.colab import drive
drive.mount('/content/drive')데이터 파일 종류 및 경로는 아래와 같다.
data_dir = "/content/drive/MyDrive/Colab Notebooks/kaggle/house_prices/data/"
submit_dir = "/content/drive/MyDrive/Colab Notebooks/kaggle/house_prices/submit/"
train_df = pd.read_csv(data_dir + "train.csv")
test_df = pd.read_csv(data_dir + "test.csv")
submission = pd.read_csv(data_dir + "sample_submission.csv")데이터 타입은 아래와 같이 확인 가능하다.
pd.set_option('display.max_rows', 100)
train_df.dtypes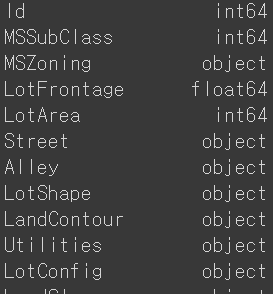
데이터 전처리를 위해 훈련 데이터와 테스트 데이터를 합친다.
- sort=False로 설정하여 섞이지 않도록 한다.
- reset.index(drop=True)로 원래 index를 삭제하고 새로이 index를 부여한다.
- train 및 test 데이터 크기를 기록하여 분리할 수도 있으나, 이 예제에서는 추후 target value 값 존재 유무로 분리한다.
all_df = pd.concat([train_df, test_df], axis=0, sort=False).reset_index(drop=True)
all_df.head(3)all_df.info()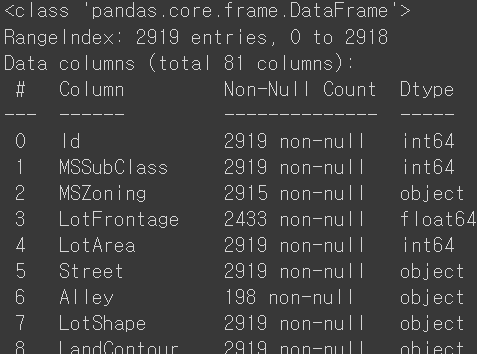
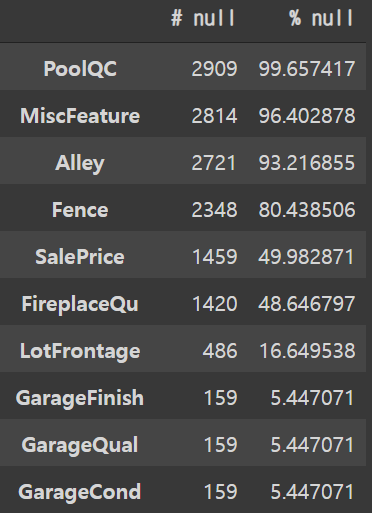
데이터가 온전하지 않기 때문에 각 feature에서 null value가 얼마나 포함되어있는지 확인이 필요하다.
null = pd.DataFrame(all_df.isnull().sum(), columns=['# null']).sort_values(by='# null', ascending=False)
null = null[null['# null'] != 0]
null['% null'] = null['# null']/len(all_df)*100
nullPoolQC, MiscFeature, Alley, Fence 특성은 null 비율이 매우 높다. 이 특성들을 처리할 방법이 필요할 것이다.
SalePrice는 Target Variable이다. Test Data가 50%정도임을 확인 가능하다.
FirePlaceQu, LotFrontage 특성 또한 null 비율이 높은 편이다.
특성 변수의 분류가 필요하다.
특성 변수는 크게 세 종류로 분류한다.
- Numerical Variable: 수치적 변수이다.
- Ordinal Variable: 순서가 있는 이산적 변수이다.
- Nominal Variable: 순서가 없는 이산적 변수이다.
기본적으로 categorical한 변수는 Ordinal Variable 혹은 Nominal Variable이다.
categories = all_df.columns[all_df.dtypes=='object']
categories
카테고리 변수의 null을 따로 살펴본다.
for cat in categories:
if cat in null.index:
print(cat + ': ' + str(null.loc[cat]['# null']))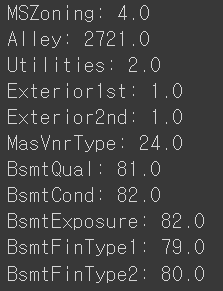
2. 개별 Feature 분석하기
아래는 노트북에서 여러 표를 보기 위한 함수이다.
def multi_table(table_list):
return HTML(
f"<table><tr> {''.join(['<td>' + table._repr_html_() + '</td>' for table in table_list])} </tr></table>")이 예제에서는 Feature의 수가 80개가 넘는다.
모두 분석하기는 어려우니 몇개만 간단히 다루겠다.
LightGBM이 뽑아준 핵심 Feature 위주로 분석해보자.
important_features = ['OverallQual', 'GrLivArea', 'Neighborhood', 'GarageCars', '1stFlrSF', 'TotalBsmtSF', 'BsmtFinSF1', 'GarageArea', 'YearBuilt', 'CentralAir']먼저 핵심 Feature를 분류한다.
numerical_vars = ['GrLivArea', 'GarageCars', '1stFlrSF', 'TotalBsmtSF', 'BsmtFinSF1', 'GarageArea', 'YearBuilt', ]
ordinal_vars = ['OverallQual']
nominal_vars = ['Neighborhood', 'CentralAir']2.1. Numerical Variable 다루기
all_df.describe().T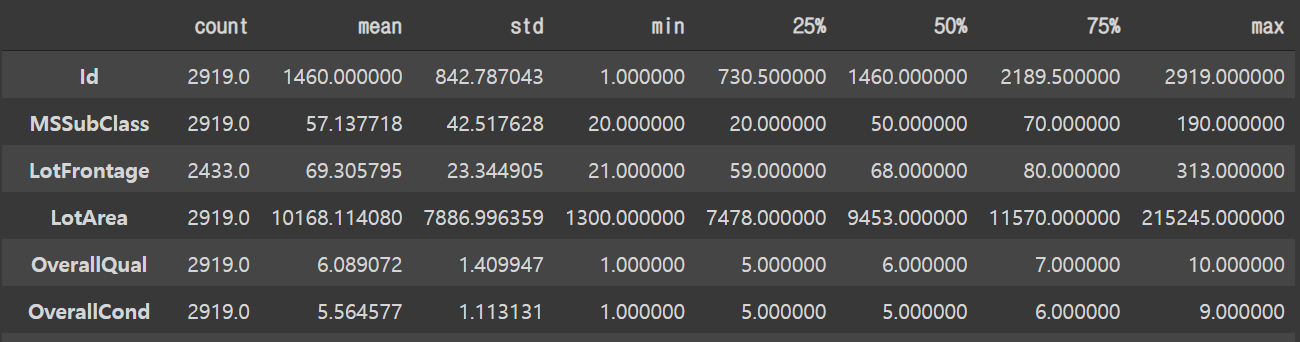
아래 코드로 수치 변수를 확인 가능하다.
train_df_num = train_df.select_dtypes(include=[np.number])모든 수치 변수가 numerical한 것은 아니다. 이들을 제외한다.
nonratio_features = ['Id', 'MSSubClass', 'OverallQual', 'OverallCond', 'YearBuilt', 'YearRemodAdd', 'MoSold', "YrSold"]num_features = sorted(list(set(train_df_num)-set(nonratio_features)))
train_df_num_rs = train_df_num[num_features]대부분의 값이 0인 변수들이 있다.
for col in num_features:
if train_df_num_rs.describe()[col]["75%"] == 0:
print(col, len(train_df_num_rs[train_df_num_rs[col]==0]))for col in num_features:
if train_df_num_rs.describe()[col]["75%"] == 0:
print(col, len(train_df_num_rs[train_df_num_rs[col]==0]))수치 변수임에도 그 값의 종류가 적은 변수들도 있다.
for col in num_features:
if train_df_num[col].nunique() < 15:
print(col, train_df_num[col].nunique())
아래 코드는 Train / Test Data의 분포를 확인한다.
Train Data와 Test Data가 유사한지 확인이 필요하다. (만약 다르다면, Train 및 Test Data를 다시 분배해야 한다.)
그리고 Train Data의 분포를 수치적으로 확인 가능하다.
def describe_numerical_values(train_df, all_df, numerical_vars):
detail_desc = []
for c in numerical_vars:
desc = pd.DataFrame(columns=['feature', 'data', 'type', 'count', 'mean', 'median', 'std', 'min', 'max', 'skew', 'null'])
desc.loc[0] = [c, 'Train', train_df[c].dtype.name, train_df[c].count(), train_df[c].mean(), train_df[c].median(), train_df[c].std(), train_df[c].min(), train_df[c].max(), train_df[c].skew(), train_df[c].isnull().sum()]
desc.loc[1] = [c, 'All', train_df[c].dtype.name, all_df[c].count(), all_df[c].mean(), all_df[c].median(), all_df[c].std(), all_df[c].min(), all_df[c].max(), all_df[c].skew(), all_df[c].isnull().sum()]
desc = desc.set_index(['feature', 'data'],drop=True)
detail_desc.append(desc.style.background_gradient())
return detail_descmulti_table(describe_numerical_values(train_df, all_df, numerical_vars))
'GrLivArea'는 Numerical Variable이다. 이를 분석해보자.
f, ax = plt.subplots(1, 2, figsize=(25, 5))
sns.distplot(analytic_train_df.GrLivArea, ax=ax[0])
sns.histplot(data=analytic_train_df, x='GrLivArea', hue='SalePriceClass', ax=ax[1], element='step')
for i in range(2):
ax[i].spines['top'].set_visible(False)
ax[i].spines['right'].set_visible(False)
ax[i].set_xlabel('GrLivArea', weight='bold', size=15)
ax[i].set_ylabel('Density', weight='bold', size=15)
ax[i].set_facecolor('#f6f5f5')
f.suptitle("GrLivArea' distribution", weight='bold', size=20)
plt.show()
GrLivArea가 커질수록 가격이 커지는 것을 알 수 있다.
def continuous_dist(data, x, y):
f, ax = plt.subplots(1, 3, figsize=(35, 10))
sns.violinplot(x=data[x], y=data[y], ax=ax[0], edgecolor='black', linewidth=5)
sns.boxplot(x=data[x], y=data[y], ax=ax[1])
sns.stripplot(x=data[x], y=data[y], ax=ax[2])
for i in range(3):
ax[i].spines['top'].set_visible(False)
ax[i].spines['right'].set_visible(False)
ax[i].set_xlabel(x, weight='bold', size=20)
ax[i].set_ylabel(y, weight='bold', size=20)
ax[i].set_facecolor('#f6f5f5')
f.suptitle(f"{y}'s distribution by {x}", weight='bold', size=25)
plt.show()continuous_dist(analytic_train_df, x='SalePriceClass', y='GrLivArea')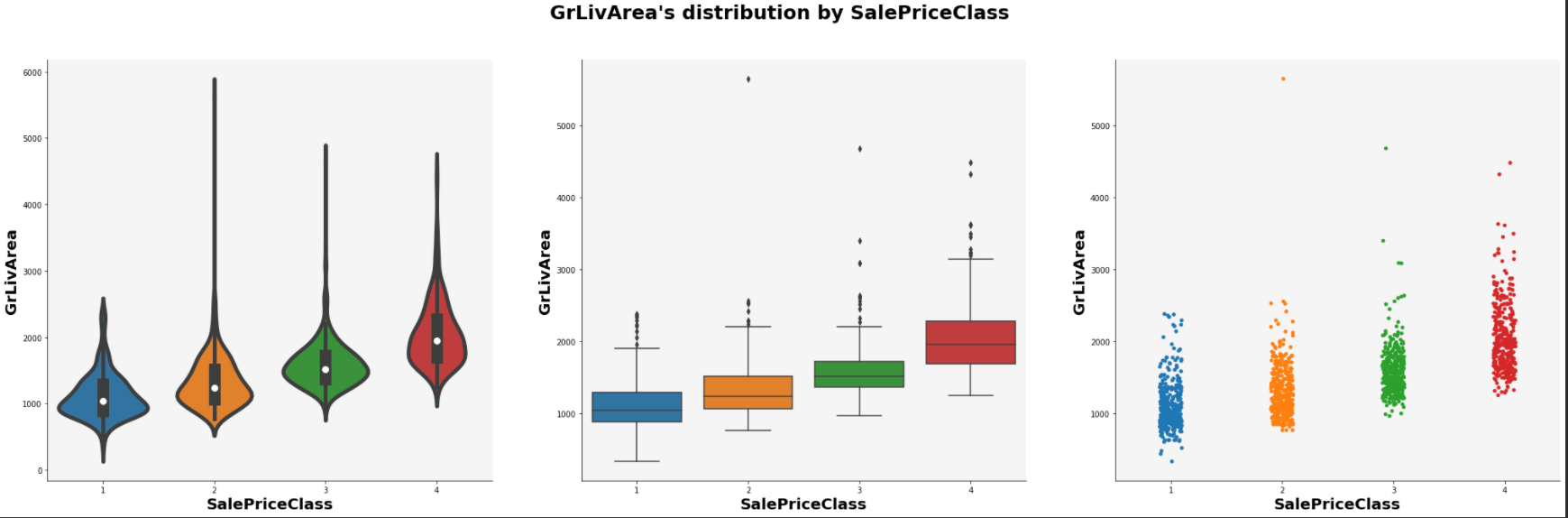
2.2. Categorical Variable 다루기
데이터를 직접 변경하는게 아니라 살펴볼 때는 따로 dataframe을 만들어서 하는 것이 아무래도 좋다.
analytic_train_df = train_df.copy()
analytic_train_df이 문제는 target variable이 연속적 변수인데, 이를 categorical 하게 나누어 보는 것도 방법이다.
4분위수 기준으로 4개 그룹으로 나눈다.
analytic_train_df['SalePriceClass'] = 4
first_quartile = analytic_train_df.SalePrice.describe()['25%']
second_quartile = analytic_train_df.SalePrice.describe()['50%']
third_quartile = analytic_train_df.SalePrice.describe()['75%']
analytic_train_df.loc[analytic_train_df['SalePrice'] < first_quartile, 'SalePriceClass'] = 1
analytic_train_df.loc[(analytic_train_df['SalePrice'] >= first_quartile) &
(analytic_train_df['SalePrice'] < second_quartile), 'SalePriceClass'] = 2
analytic_train_df.loc[(analytic_train_df['SalePrice'] >= second_quartile) &
(analytic_train_df['SalePrice'] < third_quartile), 'SalePriceClass'] = 3
analytic_train_dfanalytic_train_df.SalePriceClass.value_counts()
OverallQual은 Ordinal Variable이다. 이를 분석해보자.
def cat_dist(data, var, hue, msg_show=True):
total_cnt = data[var].count()
f, ax = plt.subplots(1, 2, figsize=(25, 8))
hues = [None, hue]
titles = [f"{var}'s distribution", f"{var}'s distribution by {hue}"]
for i in range(2):
sns.countplot(data[var], edgecolor='black', hue=hues[i], linewidth=4, ax=ax[i], data=data)
ax[i].set_xlabel(var, weight='bold', size=13)
ax[i].set_ylabel('Count', weight='bold', size=13)
ax[i].set_facecolor('#f6f5f5')
ax[i].spines['top'].set_visible(False)
ax[i].spines['right'].set_visible(False)
ax[i].set_title(titles[i], size=15, weight='bold')
for patch in ax[i].patches:
x, height, width = patch.get_x(), patch.get_height(), patch.get_width()
if msg_show:
ax[i].text(x + width / 2, height + 3, f'{height} \n({height / total_cnt * 100:2.2f}%)', va='center', ha='center', size=12, bbox={'facecolor': 'white', 'boxstyle': 'round'})
plt.show()cat_dist(analytic_train_df, var='OverallQual', hue='SalePriceClass')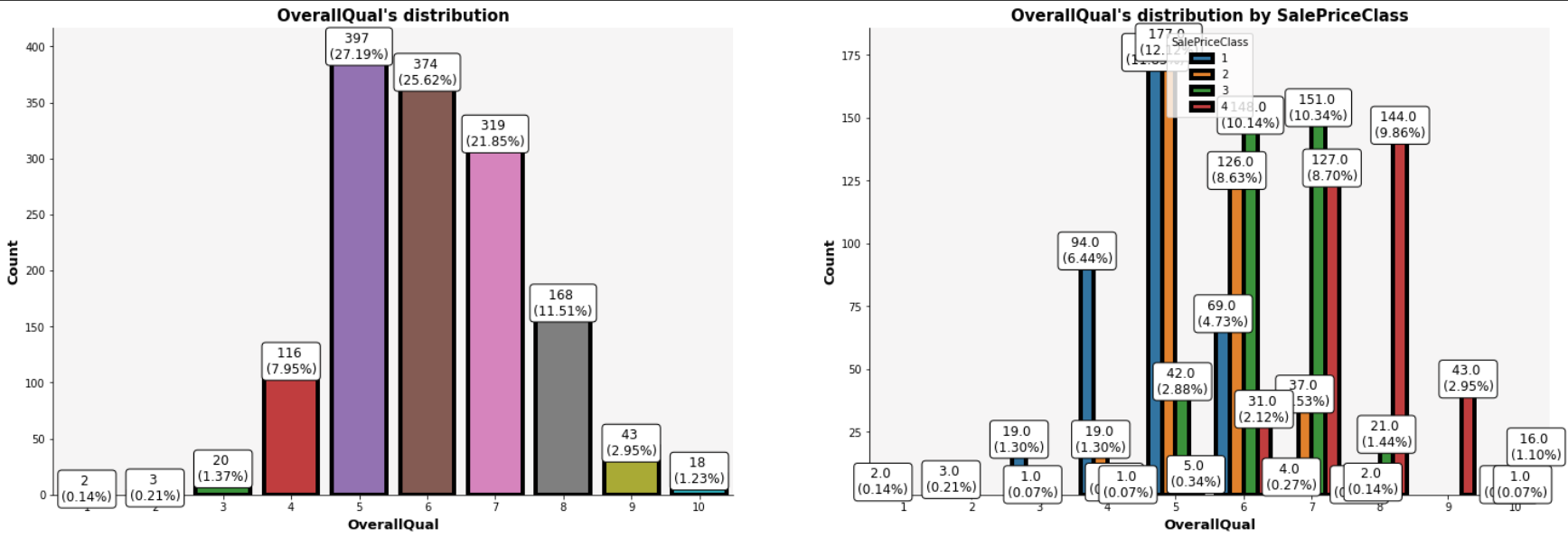
3. Base Model (Benchmark) 만들기
데이터 전처리 과정은 사용자의 주관에 따라 진행되므로, 합리적인 판단인지 중간중간 확인할 필요가 있다.
이 때 Base Model의 결과를 활용하여 데이터 전처리 과정을 정당화한다.
이 예제에서는 LightGBM을 사용한다.
class LGBM:
def __init__(self):
self.lgbm_params = {
'objective': 'regression',
'random_seed': 9999,
}
self.best_loss = None
def set_data(self, train_X, train_Y):
self.train_X = train_X
self.train_Y = train_Y
def test(self):
models = []
rmses = []
oof = np.zeros(len(self.train_X))
for train_index, val_index in KFold(n_splits=3).split(self.train_X):
X_train = self.train_X.iloc[train_index]
X_valid = self.train_X.iloc[val_index]
y_train = self.train_Y.iloc[train_index]
y_valid = self.train_Y.iloc[val_index]
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_valid, y_valid, reference=lgb_train)
model_lgb = lgb.train(self.lgbm_params,
lgb_train,
valid_sets=lgb_eval,
num_boost_round=100,
early_stopping_rounds=20,
verbose_eval=50,
)
y_pred = model_lgb.predict(X_valid, num_iteration=model_lgb.best_iteration)
tmp_rmse = np.sqrt(mean_squared_error(y_valid, y_pred))
models.append(model_lgb)
rmses.append(tmp_rmse)
oof[val_index] = y_pred
self.current_loss = sum(rmses)/len(rmses)
print('Current loss: ' + str(self.current_loss) + '(Previous best loss: ' + str(self.best_loss) + ')')
if self.best_loss == None or self.current_loss < self.best_loss:
self.best_loss = self.current_loss
if self.best_loss == self.current_loss:
self.best_models = models
actual_pred_df = pd.DataFrame({
'actual': self.train_Y,
'pred': oof
})
actual_pred_df.plot(figsize=(12, 5))
lgb.plot_importance(models[0], importance_type="gain", max_num_features=15)
4. 데이터 전처리
데이터 전처리는 훈련 및 테스트 데이터에 동시에 적용한다.
4.1. Null 데이터 처리하기
이 예제는 일반적인 데이터와 유사하게 Null 값인 데이터가 꽤 많이 있다.
Null 데이터를 잘 처리하는 것은 모델 예측력과 직결된다.
A. 대표값(중앙값, 평균 등)으로 처리하기
- Null 비율이 매우 적은 경우 사용 가능하다.
B. 다른 특성 기반으로 예측하기
- Null 비율이 매우 높은 경우 사용한다. 해당 변수가 다른 변수들을 통해 예측 가능해야 한다.
4.2. 분포
특성 변수나 목적 변수의 분포가 다소 이상한 경우, 정규 분포에 가깝게 바꾸어 주는 것이 좋다.
이는 대부분의 모델이 특성 분포가 정규 분포를 따르는 것으로 가정하고 있기 때문이다.
all_df['SalePrice'].describe()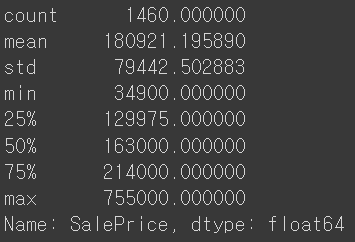
all_df['SalePrice'].plot.hist(bins=25)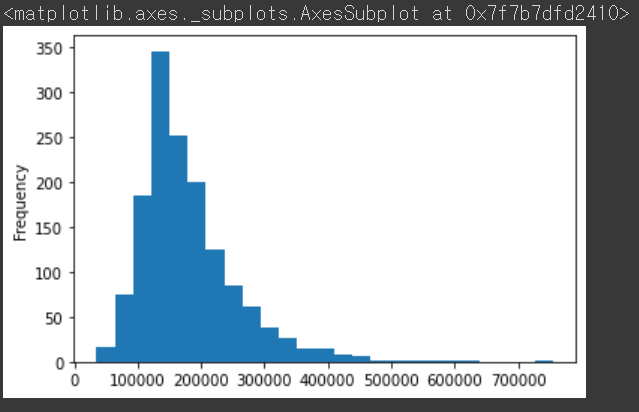
목적 변수인 'SalePrice'의 값이 다소 크고, 분포 또한 정규분포와는 거리가 있다.
여기서는 로그를 취해준다.
np.log(all_df['SalePrice']).plot.hist(bins=30)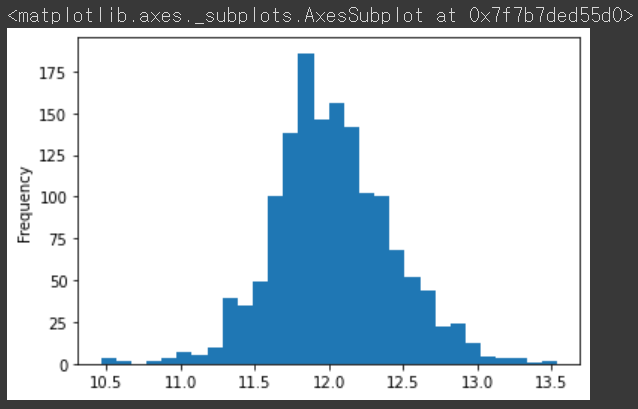
all_df['SalePrice'] = np.log(all_df['SalePrice'])4.3. 정규화
Neural Net을 사용하는 경우 데이터를 정규화하는 것이 유리하다. 이 예제에서는 생략한다.
4.4. 특성 추출
일부 특성은 그 특성을 그대로 사용하기보다는 활용하는 쪽이 더 유리하다.
all_df[['YearBuilt', 'YearRemodAdd', 'GarageYrBlt', 'YrSold']].describe()all_df['Age'] = all_df['YrSold'] - all_df['YearBuilt']4.5. 특성 삭제
필요 없는 특성은 삭제하는 것이 낫다. 예컨대 데이터가 너무 적은 경우가 그러하다.
예컨대 "PoolQC"는 데이터가 10개뿐이다.
Pool이 있는 주택이 10개란 말이다. 이런 경우에는 Pool의 존재 여부가 더 중요할 수 있다.
all_df.PoolQC.value_counts()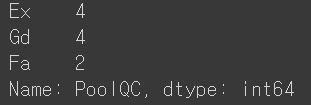
all_df.loc[~all_df["PoolQC"].isnull(), "PoolQC"] = 1
all_df.loc[all_df["PoolQC"].isnull(), "PoolQC"] = 0"MiscFeature", "Alley"또한 마찬가지이다.
이들의 존재 여부를 판단하기 위한 특성을 만들고, 이들 특성은 삭제한다.
all_df["hasHighFacility"] = all_df['PoolQC'] + all_df['MiscFeature'] + all_df['Alley']
all_df["hasHighFacility"] = all_df["hasHighFacility"].astype(int)
all_df["hasHighFacility"].value_counts()all_df = all_df.drop(['PoolQC', 'MiscFeature', 'Alley'], axis=1)4.6. 이상치 제거하기
데이터 중에는 이상한 값이 포함된 경우가 있다.
여기서 이상한 값이란, 실제로 기입이 잘못된 경우이거나 혹은 기입은 옳게 되었으나 유별난 값인 경우이다.
기입이 잘못 된 경우는, 파악만 가능하다면 제거하면 된다.
다만 기입은 옳게 되었으나 유별난 값인 경우는 처리가 까다롭다.
일반적으로 데이터가 적은 경우에는 유별난 값을 제거하는 것이 이롭다.
정규 분포의 꼬리를 확인한다.
for col in num_features:
tmp_df = train_df_num_rs[(train_df_num_rs[col] > train_df_num_rs[col].mean() + train_df_num_rs[col].std()*3) |
(train_df_num_rs[col] < train_df_num_rs[col].mean() - train_df_num_rs[col].std()*3)]
print(col, len(tmp_df))
all_df.plot.scatter(x="BsmtFinSF1", y='SalePrice')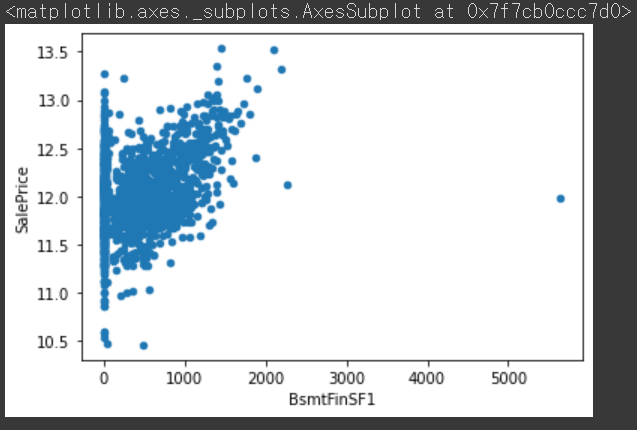
분포를 보아하니 점 하나가 걸린다. 데이터가 천오백개 밖에 안되므로 저런 데이터는 제거하는 것이 좋다.
all_df[all_df['BsmtFinSF1'] > 5000]
5. 머신 러닝
머신 러닝 팁을 간단히 적는 것은 불가능하다. 최소한의 팁만 적어둔다.
5.1. 모델 고르기
모델은 데이터의 종류와 데이터의 크기에 따라 결정한다.
데이터의 크기가 큰 경우에는 뉴럴넷 등의 최신 인공지능 기술을 사용할 수 있으나,
데이터의 크기가 적은 경우에는 SVM, LightGBM 등의 기존 기술들이 유용하다.
5.2. 모델 훈련하기
최적의 하이퍼 파라미터를 찾는 과정이다.
5.3. 모델 앙상블
여러 모델을 사용하여 예측하는 방식으로 과적합 문제를 최소화할 수 있다.
'Computer Science > Data Science' 카테고리의 다른 글
| Data Science 101 (1) | 2022.12.05 |
|---|---|
| Pandas Operations Repository (0) | 2022.11.20 |
| (py)Spark Basics (0) | 2022.10.06 |
| Google Cloud Platform Certificate; Professional Machine Learning Engineer (0) | 2022.04.12 |
| 데이터 분석 방법의 기초 - Kaggle 타이타닉 예제 (0) | 2021.11.23 |

