
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- shiba
- Convert Sorted List to Binary Search Tree
- 프로그래머스
- Generator
- iterator
- 시바견
- Substring with Concatenation of All Words
- t1
- 30. Substring with Concatenation of All Words
- Protocol
- 715. Range Module
- 운영체제
- Decorator
- Regular Expression
- Python
- Class
- 컴퓨터의 구조
- DWG
- Python Code
- 109. Convert Sorted List to Binary Search Tree
- attribute
- 밴픽
- concurrency
- 43. Multiply Strings
- 파이썬
- Python Implementation
- data science
- LeetCode
- kaggle
- 315. Count of Smaller Numbers After Self
- Today
- Total
목록시바견 (121)
Scribbling
Heapq만을 사용한 Priority Queue의 Time Complexity는 아래와 같다. Find max/min - O(1) Insert - O(logN) Remove - O(N) Remove Operation에 Linear Time이 필요하다는 것이 아쉽다. 이를 해결하기 위한 Custom Priority Queue를 만들었다. 이는 두 개의 Priority Queue를 사용하는 방식이다. 하나의 Queue는 원래 목적인 max/min heap로 사용하고, 나머지 하나의 queue를 쓰레기통으로 사용한다. Time Complexity는 아래와 같다. Find max/min - O(1) Insert - O(logN) Remove - O(logN) 다른 연산은 그다지 어렵지 않으니 Remove 연산만..
class MinStack: def __init__(self): self.stack = [] def push(self, val: int) -> None: if not self.stack: self.stack.append([val, val]) else: self.stack.append([val, min(val, self.stack[-1][1])]) def pop(self) -> None: self.stack.pop() def top(self) -> int: return self.stack[-1][0] def getMin(self) -> int: return self.stack[-1][1] # Your MinStack object will be instantiated and called as such: # ..
class Solution: def canCompleteCircuit(self, gas: List[int], cost: List[int]) -> int: culsum = 0 for i in range(len(gas)): gas[i] -= cost[i] culsum += gas[i] if culsum < 0: return -1 start_idx, culsum = 0, 0 for i in range(len(gas)): culsum += gas[i] if culsum < 0: culsum = 0 start_idx = i + 1 return start_idx
stack을 사용 class Solution: def evalRPN(self, tokens: List[str]) -> int: stack = [] predefined_tokens = ['+', '-', '*', '/'] operations = [lambda x, y : x + y, lambda x, y : x - y, lambda x, y : x * y, lambda x, y : int(x / y)] for token in tokens: if token in predefined_tokens: num2 = stack.pop() num1 = stack.pop() idx = predefined_tokens.index(token) stack.append(operations[idx](num1, num2)) els..
Relatively straightforward solution, O(N) time O(1) Memory. class Solution: def productExceptSelf(self, nums: List[int]) -> List[int]: numZero, prod, zeroidx = 0, 1, 0 for i, num in enumerate(nums): if num == 0: numZero += 1 zeroidx = i else: prod *= num if numZero >= 2: return [0] * len(nums) if numZero == 1: ret = [0] * len(nums) ret[zeroidx] = prod return ret # backward pass ret = [0] * len(n..
class Solution: def diagonalSort(self, mat: List[List[int]]) -> List[List[int]]: m, n = len(mat), len(mat[0]) starting_points = [(0, i) for i in range(n)] + [(i, 0) for i in range(1, m)] for starting_point in starting_points: array = [] y, x = starting_point while y
DFS로 쉽게 풀 수 있다. class Solution: def minReorder(self, n: int, connections: List[List[int]]) -> int: self.graph = [[] for _ in range(n)] self.connections_set = set() for u, v in connections: self.graph[u].append(v) self.graph[v].append(u) self.connections_set.add((u, v)) visited = [False] * n self.ret = 0 self.dfs(0, visited) return self.ret def dfs(self, node, visited): visited[node] = True for v..
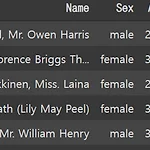 데이터 분석 방법의 기초 - Kaggle 타이타닉 예제
데이터 분석 방법의 기초 - Kaggle 타이타닉 예제
데이터 분석 방법의 기초, 두번째 포스트 Kaggle 타이타닉 예제를 다룬다. https://www.kaggle.com/c/titanic 1. 데이터 살펴보기 아래 명령어로 pandas display 옵션을 설정 가능하다. pd.set_option("display.max_columns", 50) pd.set_option("display.max_rows", 50) 데이터 타입 train_df.dtypes 기초 통계량 train_df.describe() Null 확인 train_df.isnull().sum() 2. 개별 특성 분석하기 특성 갯수 세기 train_df['Cabin'].value_counts() all_df.Pclass.value_counts().plot.bar() 개별 특성과 목적 변수 관계 ..
이 포스트에서는 캐글 주택 가격 예측 예제를 풀어보며, 데이터 분석 방법의 기초를 다져보고자 한다. 캐글 주택 가격 예측 예제 링크 https://www.kaggle.com/c/house-prices-advanced-regression-techniques 1. 데이터 불러오기 및 데이터 살펴보기 필자는 구글 코랩을 사용하며, 구글 드라이브에서 데이터를 불러온다. from google.colab import drive drive.mount('/content/drive') 데이터 파일 종류 및 경로는 아래와 같다. data_dir = "/content/drive/MyDrive/Colab Notebooks/kaggle/house_prices/data/" submit_dir = "/content/drive/My..
직선 찾기 문제 핵심은... 1) 실수 처리를 회피하기 위한 slope의 처리 2) map의 활용 from collections import defaultdict import math class Solution: def maxPoints(self, points: List[List[int]]) -> int: ret = 1 for i in range(len(points)): p1 = points[i] lineDict = defaultdict(lambda: 1) for j in range(len(points)): if i == j: continue p2 = points[j] dx = p2[0] - p1[0] dy = p2[1] - p1[1] if dx == 0: slope = (0, 1) elif dy == ..